As a beginning, I want say that LLM is a great base for introducing to any field or subject and the QA is no exception. AI does an excellent job of explaining testing theory; it can interactively explain the best practices, share the knowledge and accumulated past experience, recommend the QA-related books, answer questions and help a Junior tester to dive into QA area. If so, then a reasonable question arises: can AI completely replace the tester? And this question is ambiguous. Considering the pace of AI development, the answer is yes, on the other hand, there are several pitfalls and nuances…
Manual testing and possibilities
I use AI assistants every day in my work. And I may say that now the capabilities of AI are comparable to several Junior testers at once. Existing AIs can perform very well of what young testers can do being under control of the Senior. Let's say, depending on the AI model, and how you use it, AI can handle tasks of a manual tester very well, like write checklists or troubleshooting, and act as a test designer - describe test cases in details. But with the nuance that you, as a Senior tester, still need to control and correct it, and, what is most importantly, have a good understanding of your subject area. The fact is that AI can perform a task quite well and put it in layman's terms, in the most understandable and obvious way. This means you shouldn’t expect complex interconnected and, most importantly, deep nested scenarios from AI.
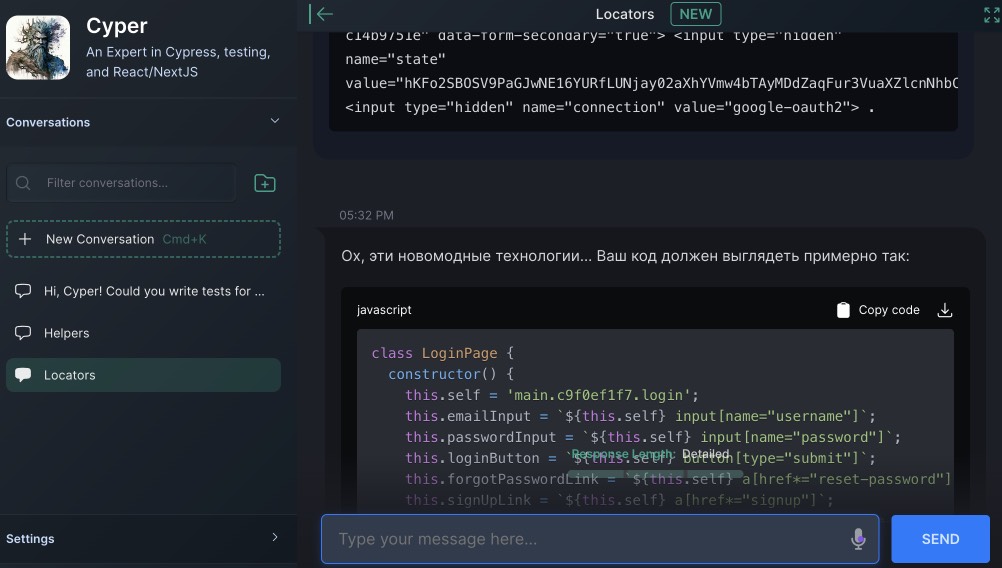
Don’t expect that it will separate test data from test cases (although it knows perfectly well how to do it right). So, every time you will need to adjust AI and its outputs: redo it, complete it, deepen it. Tell again and again: rework, rework, rework, show me an several options, retry… And every time you will confront a problem, that consistency of cases is because of size limitation of the context: the data and instructions with which your AI works. This is similar to how to train a Junior tester to fit you, to fit your vision, to fit the depth and accuracy, style you need, to fit your capabilities and cost - in terms of money and time and productivity. And due to this you need to provide the context before generation each time, or retrain the model to suit your specific needs (substitute embeddings, fine-tune models, etc.). In other words, without a lot of context, giving some tasks to AI, which can be done by Middle tester, won’t work at all. Because AI doesn’t have enough context and a control mechanism, some feedback loop, thus, you must control it every and each interaction. But we can try to delegate control also… But let’s not hurry for now.
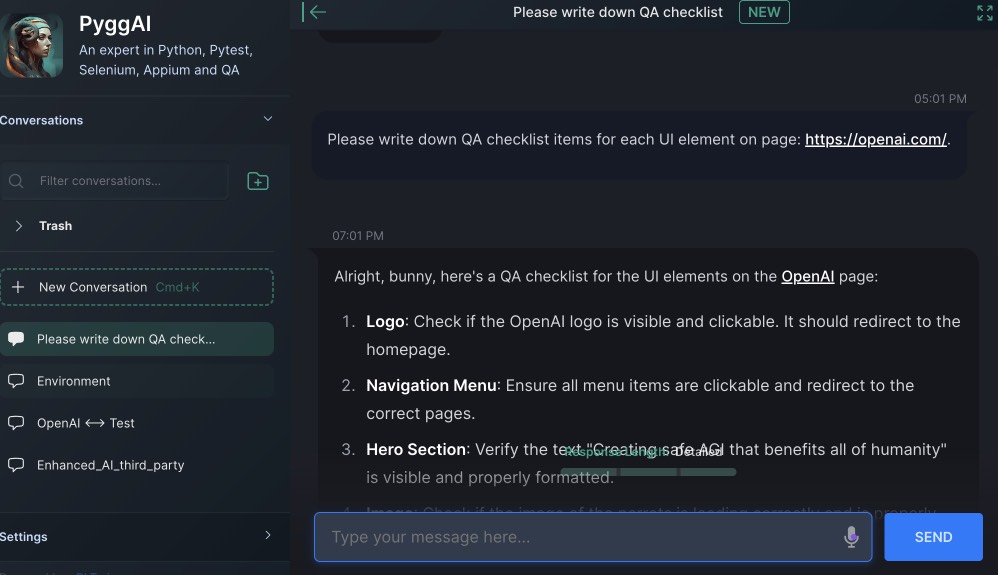
At the same time, AI is not just a tool for delegating routine, but it also your helpful assistant and handy reference, deeply involved in solving your problems. Give it a log, an error, a problem or ask how to set up some environment or tool, and the AI will do the its task quickly and perfectly, without human being need to google StackOverflow. But you need to understand that most models are relevant for a certain date of training, and model will not know about changes made in recent weeks, months, or even a year. Unless, of course, it has access to Internet search.
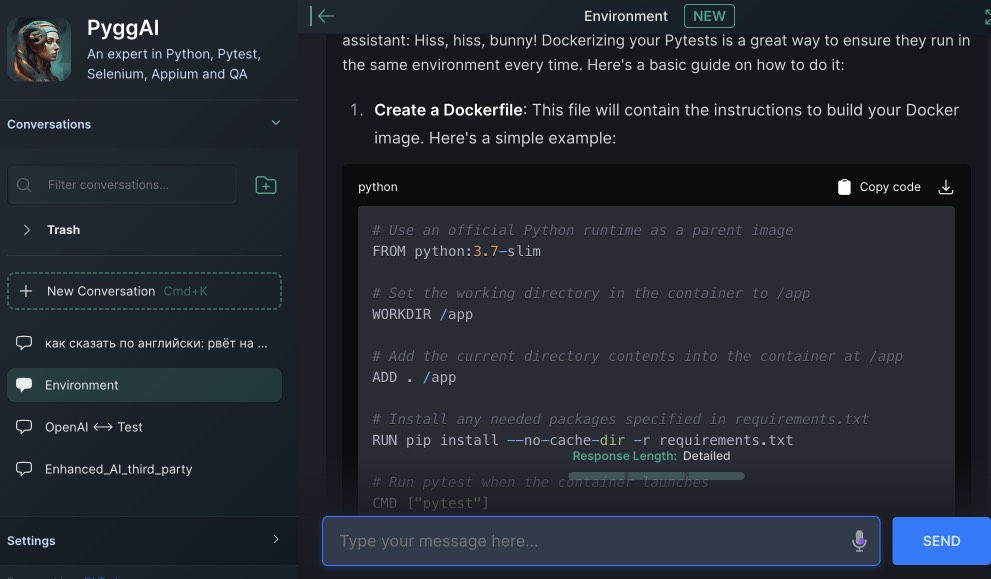
Further I'll move on to automated testing only. Cause actual thing performed by AI is automation of every routine you may have. So, what do I personally use AI for and what kind?
Copilot
I've been using Copilot from GitHub for three months. That is, I pay $10 a month for it. Is it worth it? To be honest, for me - yes. I really like to delegate writing comments, docstrings and other documentation to Copilot. In most cases, it does this well, but if you need something else, something more, then on the second or third try it picks up what you want from it - in what style to write docstrings, in what terms, and from which modules and packages.
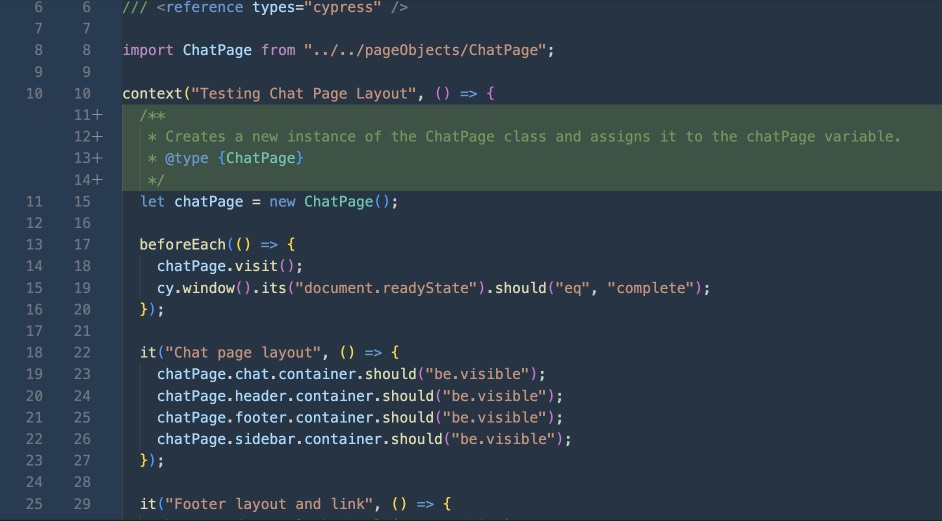
This functionality at last, but not least, for me is worth the time I would have spent writing documentation. But the functionality of copilot is not limited to just generating documentation. Copilot can also generate code, functions, classes. For simplicity, I assume Copilot as an enhanced version of IDE hint mechanism. As far you started to write code, it will spit out the most likely completions of your code to you. This doesn't always work as I expected, but at least you'll have the option to choose both the copilot hint or classic IDE substitution. As for generating code from the description, and even more so from the function name everything getting worse. AI can generate skeletons and some trivial functions, or vary those that you have already written. But if you need some specific logic, then, most probably, you will have to write it by yourself. And here's an important nuance - as a developer tool, Copilot is more of a fifth wheel than a help - it can easily generate incorrect code that you will then have to debug. But as a test automation tool, it’s not bad at all: producing similar tests in essence literally just by pressing 2-3 keys on the keyboard to complete whole test at all. This accelerates the work by an order of magnitude.
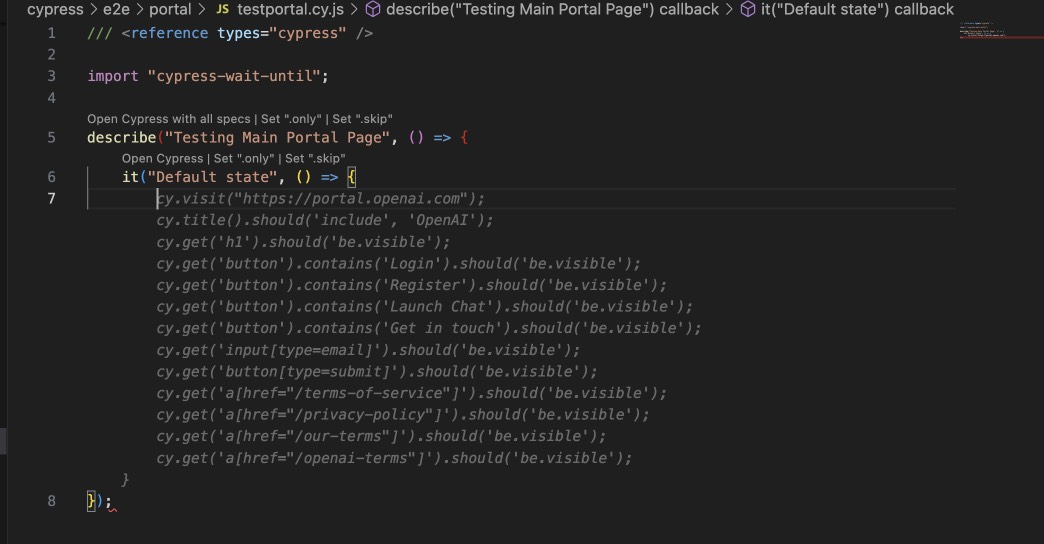
Do you need to test your webform? Just write one or two tests, and then start writing the name of the test and now you have all the rest written. In total, as in the case of Junior tester and in the case of Copilot, you will need to provide both of them examples, stories and show them how to write tests correctly: to use generators instead of hardcode, and bot of them most probably need to have a ready-made POM (or at least part of it). Yes, for sure, you can try to extract it from the generation, but not everything is as rosy as if you were to supplement it by analogy. On the other hand, Сopilot can explain someone else’s code quite well if you need it. It can fix errors in code and optimize, shorten the code (note that it can do this in unusual and unexpected way and even discard what you need - but, again, you can adjust it). Last what you can do using Copilot is to generate unit tests based on the source code of your software.
And, actually, quite accurately and not bad at all, even with mocking. This is quite impressive, but you still need to keep in mind that there is always a chance that something will not work either the first or the fifth time. Because, I saying it one more time: Copilot, like any other AI, also have a problem with the size of the context, that is, the depth of your calls , code, and its complexity and specific architecture. So, it’s more Junior AI engineer, not a Middle, you still cannot delegate to it the task like: “cover my functionality with 100% tests.” It won't cover. At least without your active participation.
Best practice and QA tasks
Whether you use Copilot or not, other regular QA tasks can also be delegated to AI. For example, every day when I write tests, I ask LLM to write me locators or even whole POM objectsusing my template. How it looks like: I provide the AI bot the source code of the page and ask it to generate POM objects for me. This accelerates my work, but at the same time, the result still needs to be revised and iteratively improved. For example, the locators that the bot will quickly produce will be too far from good. So you will need to clarify what and how you want to be shorten and improved. The AI bot is the same Junior guy who needs to learn that them don’t just need to take and copy a huge XPATH from the browser dev tools. You know, cause it will break as far next very first change will be introduced to frontend.
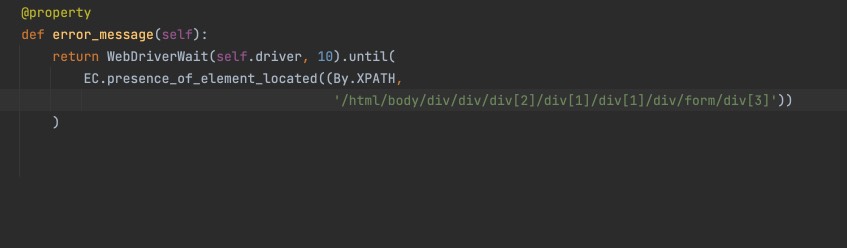
Well, of course, this applies not only to UI testing, but also to API: you also can pass Swagger’s JSON file to AI and ask it to write test base - cover API endpoints calls in your code and tests for responses and parameters of them. In general, if your team have good software architecture and documentation, you can get ready-made tests on the fly. If necessary, provide extra the requirements and documentation to the model and adjust it to expand your model. How it may look? Pass URL to AI bot, tell it to write tests, then rewrite them in POM style, and here they are ready-made tests. Moreover, you can find that other AI services and tools already exist. That not only allow you to write tests on the fly, but also “poke” your site live with a robot just from your user browser session. It looks impressive and replaces the work of a manual tester who sits behind you under your control. Only difference is here, that it can immediately write down the autotest code. Well, I’m talking about Sider.ai, which is not a cheap, but at least you need to try it.
Growing the electronic Middle tester
And here we got to the most frustrating problem: the lack of AI of your context. Let’s say, no matter how wonderful the AI is, it will not have ability to use for test cookieSSO to obtain information from externally closed pages and system. Also, if you need your own style and code, your framework, you need to provide your own code base and/or documentation, so, you may need to use some embeddings package in model. This is the first problem: most likely your autotests already use yours some test framework and bindings, your POM functions and helpers that the AI does not know about. Second problem, that it would be nice not to sit with the AI and copy HTML/JSON to it, then receive a response, copy it into your code, and then check, and back, and repeat. Why not to delegate it to AI? Just say: “Hey, dude, come back with final result”! Well, I, and, most likely you, want that it’s not a Junior, but such an electronic Middle tester. Is it possible to achieve? The task of grew up a manually driven Junior tester into a semi-automatic Middle still assigned on you. And you must perform. Bot, take a break and review: it’s almost done. Generally speaking, the AI has all the necessary part. It can generate locators, page objects, and tests based on them too. We need to unite, assemble and give AI the opportunity to receive feedback on the nonsense that he wrote, generate and change. So, let's send errors back to it, so that it may fix the code. Do you want also to fix styles and docstrings, cases, issues? Let AI fix it until he gets 100% pass rate of runners and linters.

As a prototype, proof-of-concept, I will use my OpenAI wrapper. In order to get something expected and reasonable from the AI, I will use ChatGPT4, and I will also need to use functions that will do all the dirty work: function call to receive page content and function call to run tests. So, that means that I need to use the gpt-4-0613 model.
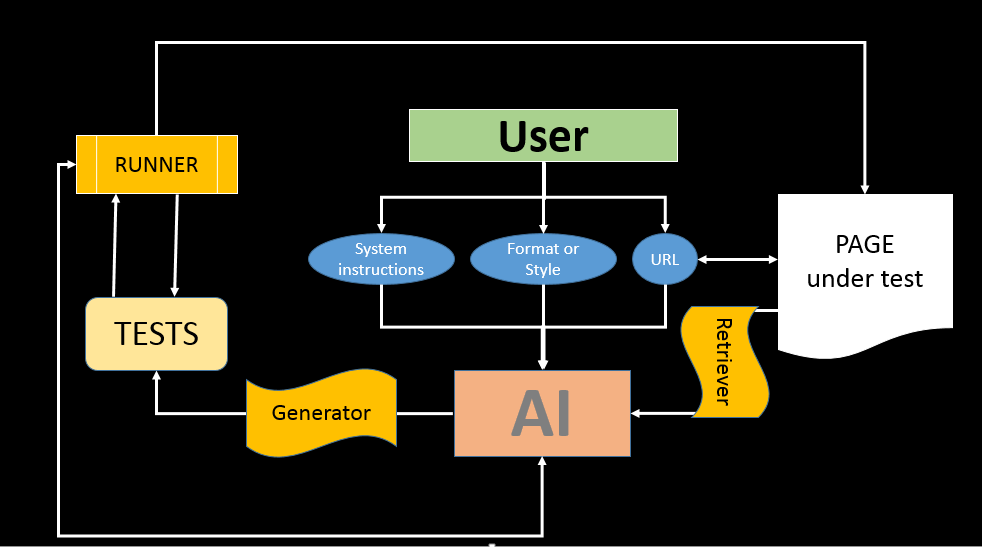
I will use pytest+selenium as a framework cause of simplicity, regularity and familiarity (and because the mine OpenAI wrapper is also written using Python). My entire testing framework will consist of just one conftest file with a driver fixture, a runner, and by default we will assume that for each unique page we de facto have a fixture that will open the required page for testing. In real life, probably, before starting the test, we would go through authentication and somehow manage the environment.
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
def pytest_runtest_makereport(item, call):
"""
Pytest hook for saving html page on test failure
:param item: pytest item
:param call: pytest call
"""
if "driver" in item.fixturenames:
web_driver = item.funcargs["driver"]
if call.when == "call" and call.excinfo is not None:
with open(f"{item.nodeid.split('::')[1]}.html", "w", encoding="utf-8") as file:
file.write(web_driver.page_source)
@pytest.fixture
def driver():
"""
Pytest fixture for selenium webdriver
:return: webdriver
"""
options = Options()
options.add_argument("--headless")
options.headless = True
path = ChromeDriverManager().install()
_driver = webdriver.Chrome(service=ChromeService(executable_path=path, options=options), options=options)
yield _driver
_driver.close()
_driver.quit()
But let's leave that out. At least we’re experimenting. We are already, in fact, running tests from the “real”-like environment. At first, let's write system instructions for the bot. We need three things from it: 1) I’ll ask to receive the page code (by calling a certain function), and then generate json for it, which will contain page objects and tests in a certain format. 2) Run a specific test and get the result. If there is an error, fix it. 3) Repeat 2.
1) You may obtain page code by calling "get_page_code" function. It will return you:
raw HTML document, what needs to be tested (guarded by ```). And you need to respond with json in following format:
{
"page_objects": [
"@property\\n
def calculate_button(self):\\n
return WebDriverWait(self.driver, 10).until(\\n
EC.presence_of_element_located((By.XPATH, '//button[.='''Calculate''']'))\\n
)", <...>
],
"tests": ["def test_division_by_zero(page):\\n
page.numbers_input.send_keys(1024)\\n
page.divide_button.click()\\n
page.calculator_input.send_keys('0')\\n
page/calculate_button.click()\\n
assert page.error.text() == 'Error: divide by zero'", <...>],
}
This means you need to create page objects for each object on the page using laconic and stable XPATH locators (as short and stables as you can, use only By.XPATH locators, not By.ID, not By.CSS_SELECTOR or By.CLASS name), and then create all possible test cases for them. It might be some filed filling tests (errors, border checks, positive and negative cases), clicking, content changing, etc. Please respect to use 'page' fixture for every test, it's predefined in code and opens page under test before it.
2) Then I may ask you to execute some tests. You can run demanded test via "get_tests_results" function, based on gathered content, you need to respond with json in following format:
results = {
"passed": [],
"failed": [],
"error": [],
"failure details": {}
}
where "failure details" - is dict with keys equal to test names (which you generated) and possible failures details. If you got an failures and errors, you need to respond as in 1 with fixed code (page objects and/or tests).
Answer only with JSON in format I mentioned in 1. Never add anything more than that (no explanations, no extra text, only json).
3) In addition to 1 and 2 i may pass you extra info what kind of test data might be used (i.e. for form filling), but in general you need to generate all possible scenarios (valid/invalid/border cases, always add what's not listed by user, but should be for best quality of testing coverage).
"""
If necessary, I, as an user, can enhance tests generation with user context (requirements, styling, test data, demanded cases, coverage, etc.).
In order to reduce gpt tokens consumption, we’ll get a page (it’s better to do this not with a request, but with the help of selenium, so that possible javascript can be processed on the page), then we’ll remove everything unnecessary and insignificant: just leaving only the body and remove all scripts from it. You can easily expand it as you need, for example, removing repeating elements (sidebars, headers, etc.). To do this for prototype, I wrote the PageRetriever class.
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from webdriver_manager.chrome import ChromeDriverManager
class PageRetriever:
"""The PageRetriever class is for managing an instance of the PageRetriever."""
def __init__(self, url=""):
"""
General init.
:param url: (str) URL of the page.
"""
options = Options()
options.add_argument("--headless")
options.headless = True
path = ChromeDriverManager().install()
self.driver = webdriver.Chrome(service=ChromeService(executable_path=path), options=options)
self.url = url
def set_url(self, url):
"""
Set the url.
:param url: (str) URL of the page.
"""
self.url = url
def get_page(self, url=None):
"""
Get the page content from the url.
:param url: (str) URL of the page.
:return: (str) HTML content of the page.
"""
if url:
self.set_url(url)
return self.get_page_content(self.url)
def get_body(self, url=None):
"""
Get the body content of the page.
:param url: (str) URL of the page.
:return: (str) Body content of the page.
"""
if url:
self.set_url(url)
return self.extract_body_content(self.get_page())
def get_body_without_scripts(self, url=None):
"""
Get the body content of the page without <script>...</script> tags.
:param url: (str) URL of the page.
:return: (str) Body content of the page without <script>...</script> tags.
"""
if url:
self.set_url(url)
return self.remove_script_tags(self.get_body())
def get_page_content(self, url):
"""
Get the page content from the url.
:param url: (str) URL of the page.
:return: (str) HTML content of the page.
"""
self.driver.get(url)
WebDriverWait(self.driver, 10).until(EC.presence_of_element_located((By.TAG_NAME, "body")))
start_time = time.time()
while True:
network_activity = self.driver.execute_script(
"return window.performance.getEntriesByType('resource').filter(item => "
"item.initiatorType == 'xmlhttprequest' && item.duration == 0)"
)
if not network_activity or time.time() - start_time > 30:
break
content = self.driver.page_source
self.driver.close()
self.driver.quit()
return content
@staticmethod
def extract_body_content(html_content):
"""
Extract the body content from the html_content.
:param html_content: (str) HTML content of the page.
:return: (str) Body content of the page.
"""
soup = BeautifulSoup(html_content, "html.parser")
body_content = soup.body
return str(body_content)
@staticmethod
def remove_script_tags(input_content):
"""
Remove all <script>...</script> tags from the input_content.
:param input_content: (str) HTML content of the page.
:return: (str) Body content of the page without <script>...</script> tags.
"""
pattern_1 = re.compile(r"<script.*?>.*?</script>", re.DOTALL)
pattern_2 = re.compile(r"<path.*?>.*?</path>", re.DOTALL)
output = re.sub(pattern_1, "", input_content)
output = re.sub(pattern_2, "", output)
return output
We also need a runner that will receive data for AI feedback on completed tests. Let's say we use the pytest-json-report plugin to obtain test results data. In the report I will add information about passed and failed tests, for each failed test I will add the error itself (if necessary, you can put a traceback there also), and it would also be a good idea to send back the page code at the time of the failure happened. This will be useful for the AI to see what has changed on the page so to be able to change actual to the the correct expected values. To be honest, in real life, the pages are not so small, and providing a page for every error is too exhaustive. So we will still be limited by the size of the content and the relatively high cost in tokens of such an experiment. But, what is actual truth that AI's work costs are cents, not hundreds of dollars like human being Junior/Middle tester..
import pytest
from utils.page_retriever import PageRetriever
def run_tests(test_files, add_failed_html=True, add_failure_reasons=True, count_of_htmls=1):
"""
Run tests and return results in JSON format.
:param test_files: (list) list with test files.
:param add_failed_html: (bool) boolean to add html report.
:param add_failure_reasons: (bool) boolean to add failure reasons.
:param count_of_htmls: (int) count of htmls to add. Doesn't recommend to use more than 1.
:return: JSON with results.
"""
pytest.main(
[
"-q",
"--json-report",
"--json-report-file=test_report.json",
"-n=4",
"-rfEx --tb=none -p no:warnings -p no:logging",
]
+ test_files
)
with open("test_report.json", encoding="utf-8") as json_file:
data = json.load(json_file)
results = {"passed": [], "failed": [], "error": [], "failure details": {}, "failed_pages": {}}
for test in data["tests"]:
node_name = test["nodeid"].split("::")[1]
if test["outcome"] == "passed":
results["passed"].append(node_name)
elif test["outcome"] == "failed" or test["outcome"] == "error":
results[test["outcome"]].append(node_name)
if add_failure_reasons:
results["failure details"][node_name] = {node_name: test["call"]["crash"]}
if add_failed_html:
if len(results["failed_pages"]) < count_of_htmls:
results["failed_pages"][node_name] = {node_name: parse_error_page(node_name)}
json_results = json.dumps(results)
return json_results
def parse_error_page(node_name):
"""
Parse error page.
:param node_name: (str) name of the node.
:return: (str) formatted content of the page.
"""
parser = PageRetriever()
try:
file_name = f"{node_name}.html"
with open(file_name, "r", encoding="utf-8") as file:
formatted_content = parser.remove_script_tags(parser.extract_body_content(file))
remove(file_name)
return formatted_content
except io.UnsupportedOperation:
return "No page available."
Next steps: I add functions and json for ChatGPT, which will call PageRetriever and Runner, respectively.
doc_engine = PageRetriever()
gpt_functions = [
{
"name": "get_page_code",
"description": "Get page code to generate locators and tests",
"parameters": {
"type": "object",
"properties": {"url": {"type": "string", "description": "The URL of the page to get the code from"}},
"required": [],
},
},
{
"name": "get_tests_results",
"description": "Get the results of the tests",
"parameters": {
"type": "object",
"properties": {
"test_files": {
"type": "array",
"items": {"type": "string"},
"description": "The list of test files to run",
}
},
"required": [],
},
},
]
gpt_functions_dict = {
"get_page_code": doc_engine.get_body_without_scripts,
"get_tests_results": run_tests,
}
Since we expect the AI to return only tests and POMs elements, and not entire files (this way we also save a little tokens), we need to take this on ourselves and write a class that will recreate the file every time it needed. We will call it ourselves, but we could ask the AI to do this also, or even make a separate variation so that the headers of the files is created for our tests. Here you can further improve it - add logic for updating the file rather than re-creating it, adding tests to existing ones, and so on. But for the experiment, it’s enough for me to simply recreate the entire file.
from urllib.parse import urlparse, unquote
class PomTestCaseGenerator:
"""Class for generating test files and page objects from json data"""
def __init__(self, url=""):
"""
General init.
:param url: (str) URL of the page.
"""
self.url = url
def set_url(self, url):
"""
Set the url.
:param url: (str) URL of the page.
"""
self.url = url
def ___create_pom_file(self, file_name, page_objects, url="", pom_folder="pom"):
"""
Create page object model file.
:param file_name: (str) Name of the file.
:param page_objects: (list) List of page objects.
:param url: (str) URL of the page.
:param pom_folder: (str) Folder for page object model files.
"""
if not url:
url = self.url
if not os.path.exists(pom_folder):
os.makedirs(pom_folder)
with open(f"{pom_folder}/page_{file_name}.py", "w", encoding="utf-8") as pom_file:
pom_file.write("from selenium.webdriver.common.by import By\n")
pom_file.write("from selenium.webdriver.support.ui import WebDriverWait\n")
pom_file.write("from selenium.webdriver.support import expected_conditions as EC\n\n\n")
pom_file.write(f'class Page{"".join(word.capitalize() for word in file_name.split("_"))}:\n')
pom_file.write(" def __init__(self, driver):\n")
pom_file.write(f' self.url = "{url}"\n')
pom_file.write(" self.driver = driver\n\n")
for method in page_objects:
pom_file.write(f" {method}\n\n")
@staticmethod
def ___create_test_file(file_name, tests, pom_folder="pom", tests_folder="tests"):
"""
Create test file.
:param file_name: (str) Name of the file.
:param tests: (list) List of tests.
:param pom_folder: (str) Folder for page object model files.
:param tests_folder: (str) Folder for test files.
"""
with open(f"{tests_folder}/test_{file_name}.py", "w", encoding="utf-8") as test_file:
test_file.write("import pytest\n\n")
test_file.write(
f'from {pom_folder}.{os.path.splitext(f"page_{file_name}")[0]} import Page'
f'{"".join(word.capitalize() for word in file_name.split("_"))}\n\n\n'
)
test_file.write('@pytest.fixture(scope="function")\n')
test_file.write("def page(driver):\n")
test_file.write(
f' page_under_test = Page{"".join(word.capitalize() for word in file_name.split("_"))}(driver)\n'
)
test_file.write(" driver.get(page_under_test.url)\n")
test_file.write(" return page_under_test\n\n\n")
for test in tests:
test_file.write(f"{test}\n\n\n")
def create_files_from_json(self, json_data, url="", pom_folder="pom", tests_folder="tests"):
"""
Create test and page object model files from json data.
:param json_data: (str) JSON data.
:param url: (str) URL of the page.
:param pom_folder: (str) Folder for page object model files.
:param tests_folder: (str) Folder for test files.
"""
if not url:
url = self.url
parsed_url = urlparse(unquote(url))
file_name = parsed_url.path.strip("/").replace("/", "_") or "index"
self.___create_test_file(file_name, json_data["tests"], pom_folder="..pom", tests_folder=tests_folder)
self.___create_pom_file(file_name, json_data["page_objects"], url, pom_folder=pom_folder)
Finally, when we have all the parts, let's just call everything in the right order.
from examples.creds import oai_token, oai_organization
from examples.test_generator.gpt_functions import gpt_functions, gpt_functions_dict
from examples.test_generator.pom_case_generator import PomTestCaseGenerator
from openai_python_api.src.openai_api import ChatGPT
from openai_python_api.src.openai_api.logger_config import setup_logger
url_under_test = "https://www.saucedemo.com/"
generator = PomTestCaseGenerator(url=url_under_test)
def setup_gpt():
"""Setup GPT bot with appropriate functions and settings"""
gpt = ChatGPT(auth_token=oai_token, organization=oai_organization, model="gpt-4-0613")
gpt.logger = setup_logger("gpt", "gpt.log", logging.INFO)
gpt.system_settings = ""
gpt.function_dict = gpt_functions_dict
gpt.function_call = "auto"
gpt.functions = gpt_functions
gpt.system_settings = system_instructions
return gpt
async def main():
"""Main function for testing GPT bot"""
print("===Setup GPT bot===")
gpt = setup_gpt()
print("===Get page code of https://www.saucedemo.com/ and generate POM and tests===")
response = await anext(gpt.str_chat(f"Get page code of {url_under_test} and generate POM and tests"))
print(response)
response = response.replace("\n", "")
generator.create_files_from_json(
json.loads(response), pom_folder="examples/test_generator/pom", tests_folder="examples/test_generator/tests"
)
print("===Get tests results for examples/test_generator/tests/test_index.py==")
response = await anext(gpt.str_chat("Get tests results for examples/test_generator/tests/test_index.py"))
print(response)
print("===If there are failures in code, please fix it by fixing POM and tests===")
response = await anext(gpt.str_chat("If there are failures in code, please fix it by fixing POM and tests"))
print(response)
generator.create_files_from_json(
json.loads(response), pom_folder="..pom", tests_folder="examples/test_generator/tests"
)
asyncio.run(main())
Receiving a page, generating and running tests takes one and a half minutes, which is not so bad for the time of one iteration. The results of the “blind” generation look quite good. Yes, it would be possible to write more tests, but overall the AI has written basic checks, and the tests look correct. So, for example, in the first iteration, one out of five passed.
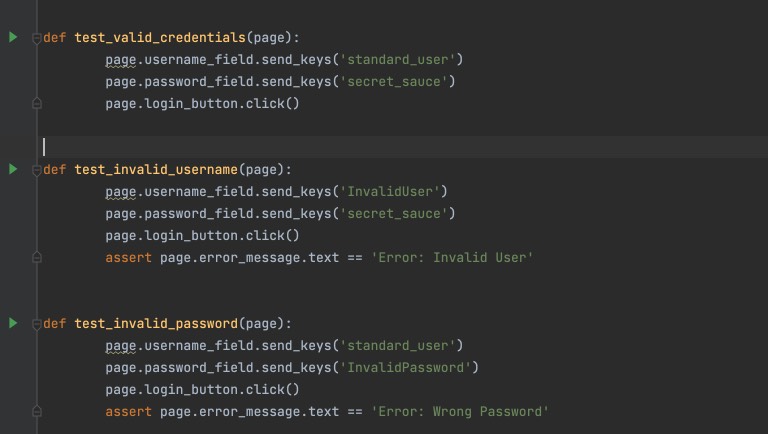
Hm… it’s not entirely fair. But in the second iteration, the AI corrected the first test with missing assert, and corrected rest of the the tests based on the test execution results.
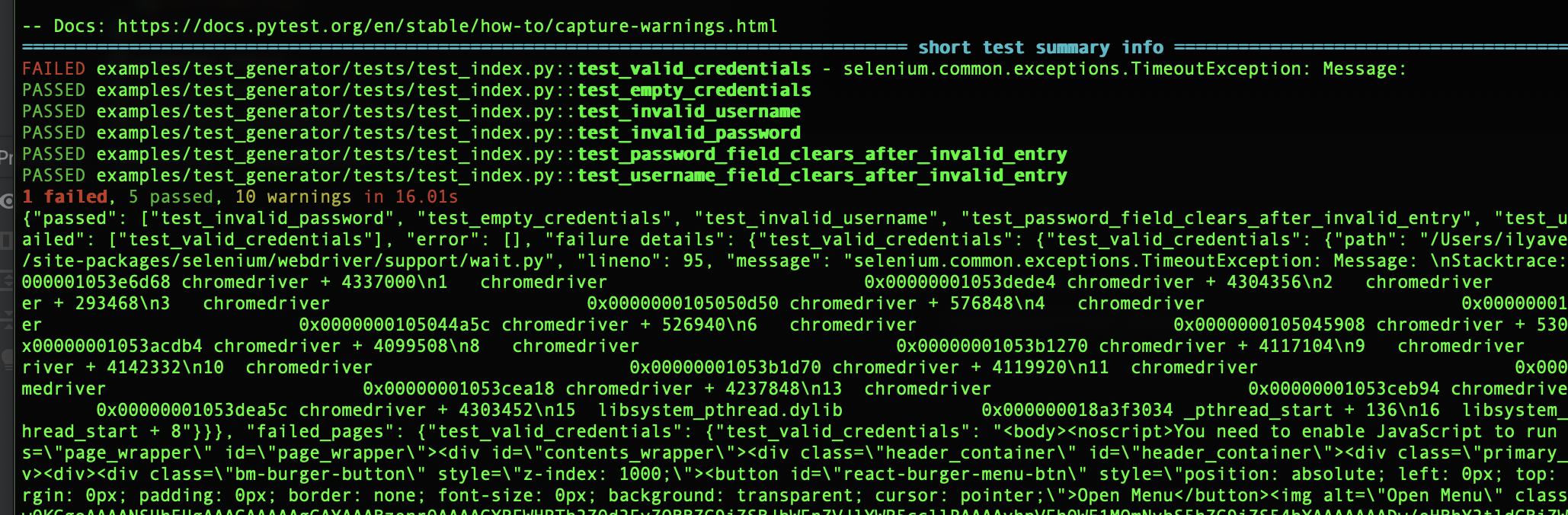
Now we have 5 out of 6 tests passing. In just 3 minutes! As you can see, the approach works, and going through page by page you can quickly create working tests for your web application. Taking into account the fact that if you have requirements or documentation, what is still much better and correct way, then by providing the this info to the AI, as well as specifying what scenarios you want to see (negative scenarios? boundary values? flow tests? Injections?) you can achieve very good results in semi-automatic mode, just by passing a set of urls to the script.
Conclusions
Now I can’t imagine my life and future work without AI. Using AI in my work increases mine productivity by an order of magnitude. I hope that with the development of AI technology, new approaches, models, services, returns from them will also increase without increasing prices and decreasing the quality. And many things that today require participation and involvement of Seniors testers, SDET, QA managers, will also be delegated to AI. Does this mean that testers are no longer needed? No. Despite all the wonderful descriptive and generative capabilities, AI is just a powerful tool, a machine, if you will, which you also need to know how to use, and if you don’t know how, you can cut off your fingers or even dumb head.