I hate API testing. I never liked it. Why recruiters are still asking about it? Moreover, some companies split automation testing into two parts: UI and API. And, I always wanted to ask: are you serious? Do you write hilarious tests to get states only via UI? Or you spend huge amount of time to generate test data, reuse same accounts, data, what leads to pesticide paradox? Isn't better to get/prepare state and data via API or even API mocking? This will significantly reduce time and efforts for UI automation testing. Moreover, it will make your tests more stable and reliable. And, you will be able to cover more cases with less efforts. It's question for full regression, but for smoke poking API endpoints may be a good idea, that at least backend works well, plus general pages and interfaces exists. So, why we need to write tests manually, split from other testing processes, and not use the same tools for testing as for development?
API calls. Do you use it?
Wrapped into fixtures...
Used in code to get right state to test UI components...
I still can't get how you can write autotests without this approach. Because usually splitting tests looks like you have two different projects, with different tools, different languages, different approaches, and different people. And, it's not a good idea. It's better to have one project, one language, one approach, and one team. So, if you're using Selenium and pytest, why do you need some extra tool for API testing? I.e. Postman? Well, if your backend engineer already did it for you, you can just use it for sure... but also without integration with your UI tests.
But, if you need to write tests manually, you can use Postman, but it's not the best idea. Why you need it, if you can poke endpoints with curl?
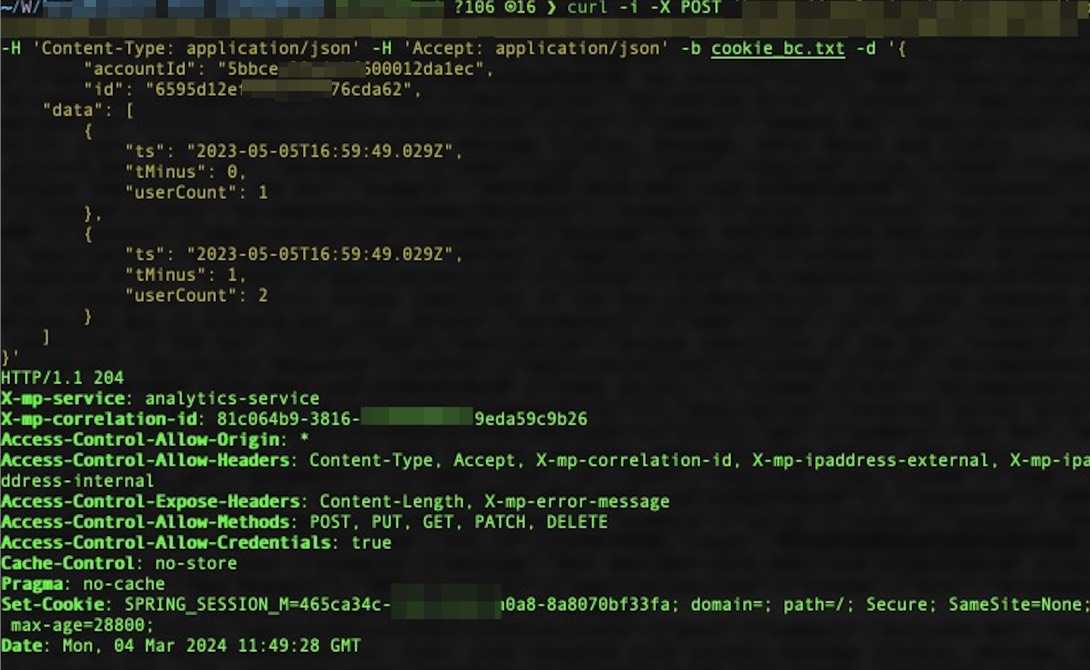
For sure, you need to know which endpoints you have, what they do, and how to use them. And, here comes project documentation. Let's stay aside Jira/Confluence based docs, or, even worse, paper-like docs. I hope that your developers already uses self-documented code and APIs, like FastAPI, which creates ReDoc or Swagger documentation for you. And, if you have it, you can use it for your tests. To poke with Swagger UI instead of pure curl...
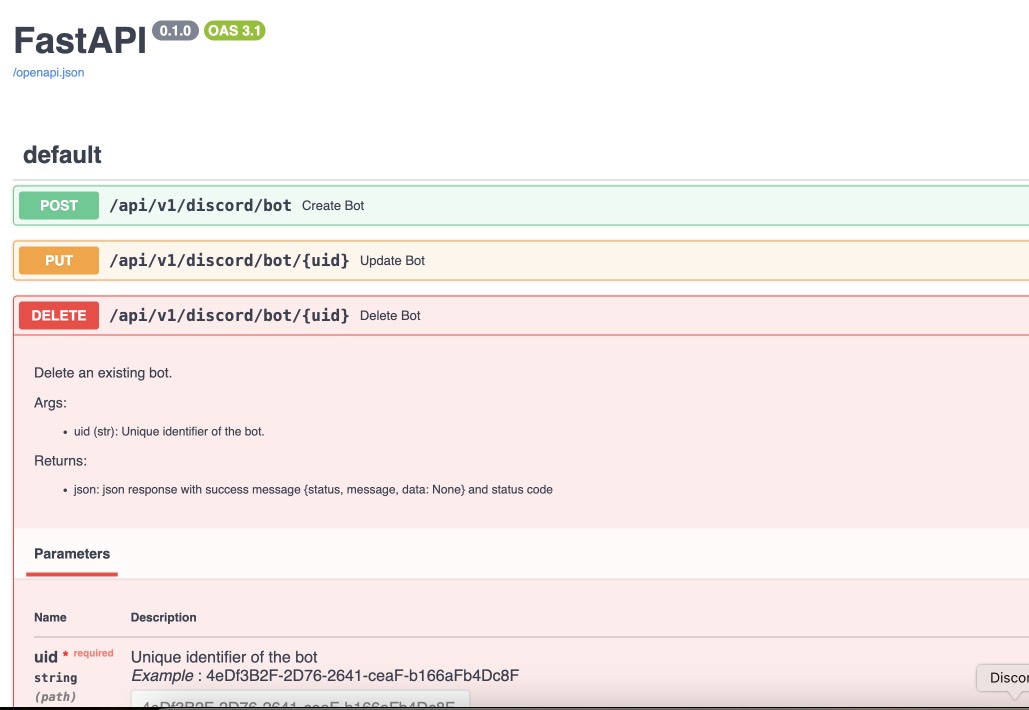
But it's still separate entity, outside of automation testing infrastructure. And, it's not good. It's better to have it inside of your project, and use it as a part of your tests. And, it's possible. Let's try to automate API testing using Swagger and few Python magic. Let's write test generator for such purpose.
Swagger Parser
At the beginning, let's create a class for parsing Swagger.
class SwaggerParser:
"""Swagger parser class"""
def __init__(self, url):
"""
Args:
General init
url (str): swagger url
"""
self.url = url
self.endpoints = {}
self.content = {}
self.schemes = {}
Utility functions
AT first, let's add some utility functions. I.e. camelCase to snake_case converter. It's useful for converting endpoint names (well, let's assume your devs using Java style) to function names into snake notation.
@staticmethod
def camel_to_snake(name):
"""
Method to convert camelCase to snake_case
Args:
name (str): string to convert
Returns:
str: converted string
"""
return "".join(["_" + i.lower() if i.isupper() else i for i in name]).lstrip("_")
Next, we need some method to load Swagger page as JSON to class variable, raw page already contains all needed data, and we can use it as is right from Swagger url.

Because we well get schemes from Swagger page right from JSON format, we can use just json.loads here, but for payload generation we need converters from string to JSON (i.e. wrap out quotes and symbols). We'll need it later...
@staticmethod
def dict_to_str(any_dict):
"""
Method to convert dict to string
Args:
any_dict (dict): dict to convert
Returns:
str: converted dict
"""
return "{" + ", ".join(f"'{k}': {v}" for k, v in any_dict.items()) + "}"
Obtain data
Ok, let's go back to Swagger. Let's get swagger content finally:
import json
import requests
def load_page(self):
"""Method to load swagger page as json to class variable"""
response = requests.get(self.url, timeout=10)
self.content = json.loads(response.text)
Now need to get schemes from Swagger page and save it to class variable.
def get_schemes(self):
"""Method to get schemes from swagger page and save it to class variable"""
self.schemes = self.content.get("components", {}).get("schemas", {})
Schemas is needed to figure out how to generate payload for POST, PUT, PATCH requests, it's crucial to generate different screnarios and tests.
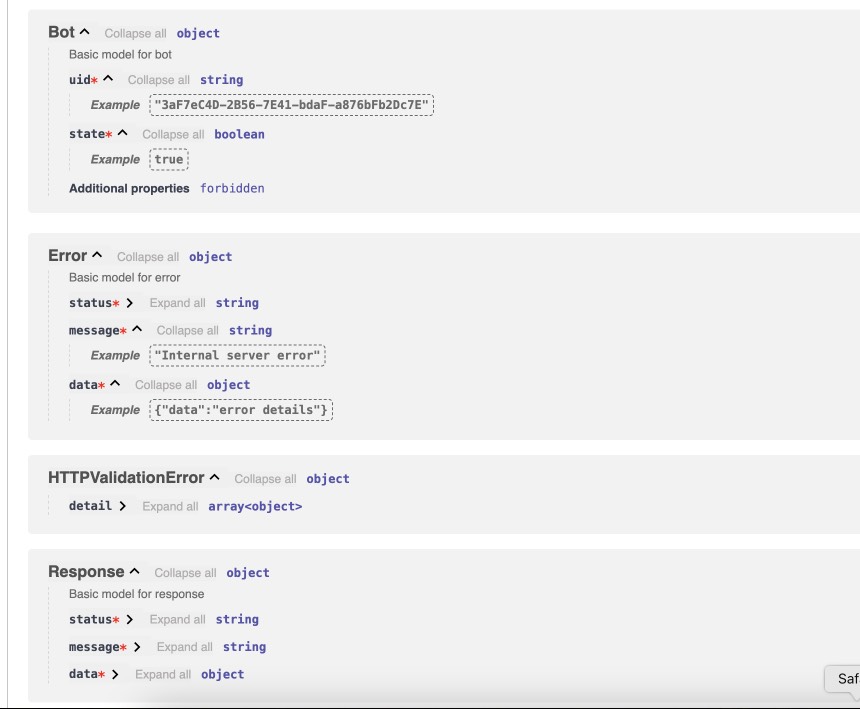
But, at first, right after figuring out schemes, we need to get endpoints itself from Swagger page and save it to class variable.
import json
import requests
def get_endpoints(self, url=None):
"""
Method to get endpoints from swagger url
Args:
url (str): swagger url
Returns:
list: endpoints
"""
url = url if url else self.url
response = requests.get(url, timeout=10)
data = json.loads(response.text)
base_url = data["servers"][0]["url"]
paths = data["paths"]
endpoints = []
for path, methods in paths.items():
for method in methods:
endpoints.append(f"{method.upper()}: {base_url}{path}")
return endpoints
Then, we need to parse Swagger page and save endpoints to class variable.
def parse_endpoints(self):
"""Method to parse swagger page and save endpoints to class variable"""
for path, path_data in self.content["paths"].items():
for method, method_data in path_data.items():
endpoint_name = f"{method}{path.replace('/', '_')}"
self.endpoints[endpoint_name] = method_data
Most probably, you have different endpoints for different services (let's name them 'backstages'), and you need to split them into internal and external part. So, let's add some methods to get backstage and external suffix from Swagger URL.
def get_backstage(self):
"""
Method to get backstage name from swagger url
Returns:
str: backstage name
"""
return self.content["servers"][0]["url"].split(".")[0].split("//")[-1]
def get_external(self):
"""
Method to get external suffix name from swagger url
Returns:
str: external name
"""
if self.url.endswith("-external"):
return "-external"
return ""
Processing entities
After we got schemas, we need process them. Let's add some methods to process param and return wrong, missing and correct values in according to param type.
def process_schema(self, scheme_name):
"""
Method to process scheme and return wrong, missing and correct values
Args:
scheme_name (str): scheme name
Returns:
tuple: wrong, missing and correct values
"""
scheme = {k.lower(): v for k, v in self.schemes.items()}[scheme_name]
correct_scheme = {}
wrong_scheme = {}
missed_scheme = {}
for prop, details in scheme["properties"].items():
prop_type = details.get("type", "")
wrong_scheme[prop], correct_scheme[prop], missed_scheme[prop] = self.process_param(param_type=prop_type)
return self.dict_to_str(wrong_scheme), self.dict_to_str(missed_scheme), self.dict_to_str(correct_scheme)
Ok, it's time to say how to deal with parameters. Let's add some method to process param and return wrong, missing and correct values. It's a bit tricky and I want to explain it first. We need to generate wrong, missing and correct values for each parameter. It's not so easy, because we need to figure out what type of parameter we have. It can be string, integer, number, boolean, array, or even some custom type. And, we need to generate wrong, missing and correct values for each type. For example, for string it can be empty string, random string, random number, random float, etc. For integer it can be random float, random string, etc. And, for custom type we need to process it recursively. So, let's add some method to process param and return wrong, missing and correct values. Also, if it contains some boundaries and limits, we need to process it too, using boundary-testing approach. Also, some parameters might have only some specific values, like enums, and we need to process it too. And, of course, we need to process it recursively, if it's a custom type (is it derived from some other type?).
import random
# pylint: disable=too-many-branches,too-many-statements
def process_param(self, param=None, param_type=None):
"""
Method to process param and return wrong, missing and correct values
Args:
param (dict): param to a process
param_type (str): param type
Returns:
tuple: wrong, missing and correct values
"""
param_type = param_type if param_type else param["schema"].get("type", "")
schema = param.get("schema", {}) if param else {}
min_boundaries = [
"minimum",
"min",
"min_value",
"restricted",
"restricted_value",
] # Add all possible min names here
max_boundaries = ["maximum", "max", "max_value"] # Add all possible max names here
wrong_value = missing_value = correct_value = None
if param_type == "string":
enum_values = schema.get("enum") if schema else None
if enum_values:
correct_value = random.choice(enum_values)
wrong_value = "random_string()" # Assuming this will not generate a value in enum_values
missing_value = "''"
return wrong_value, missing_value, correct_value
wrong_value = random.choice(["random_int_number()", "random_float_number()"])
missing_value = "''"
correct_value = "random_string()"
elif param_type == "integer":
if isinstance(schema, dict):
for min_boundary in min_boundaries:
if min_boundary in schema:
wrong_value = str(schema[min_boundary] - 1)
correct_value = str(schema[min_boundary])
missing_value = "None"
else:
wrong_value = random.choice(["random_float_number()", "random_string()"])
missing_value = "None"
correct_value = "random_int_number()"
for max_boundary in max_boundaries:
if max_boundary in schema:
wrong_value = str(schema[max_boundary] + 1)
correct_value = str(schema[max_boundary])
missing_value = "None"
else:
wrong_value = random.choice(["random_float_number()", "random_string()"])
missing_value = "None"
correct_value = "random_int_number()"
else:
wrong_value = random.choice(["random_float_number()", "random_string()"])
missing_value = "None"
correct_value = "random_int_number()"
elif param_type == "number":
if isinstance(schema, dict):
for min_boundary in min_boundaries:
if min_boundary in schema:
wrong_value = str(schema[min_boundary] - 1)
correct_value = str(schema[min_boundary])
missing_value = "None"
else:
wrong_value = "random_string()"
missing_value = "None"
correct_value = "random_float_number()"
for max_boundary in max_boundaries:
if max_boundary in schema:
wrong_value = str(schema[max_boundary] + 1)
correct_value = str(schema[max_boundary])
missing_value = "None"
else:
wrong_value = "random_string()"
missing_value = "None"
correct_value = "random_float_number()"
else:
wrong_value = "random_string()"
missing_value = "None"
correct_value = "random_float_number()"
elif param_type == "boolean":
wrong_value = random.choice(["random_float_number()", "random_string()", "random_int_number()"])
missing_value = "None"
correct_value = random.choice(["True", "False"])
elif param_type == "array":
wrong_value = random.choice(["random_float_number()", "random_string()", "random_int_number()"])
missing_value = "None"
correct_value = "[]"
elif param_type == "" and param["name"].lower() in (s.lower() for s in self.schemes):
wrong_value, missing_value, correct_value = self.process_schema(param["name"])
else:
print(f"\t\tWarning! Unknown param type: {param_type}")
return None, None, None
return wrong_value, missing_value, correct_value
Oh, yeah, it looks not so good because of many branches. And I hope, you can refactor it on your needs. But, it's a good start.
Connections
Well, you know, that we need to follow DRY and SOLID principles. So, I assume, that many tests will use same endpoint, and we need to generate connection for it. And, we need to generate it in a way, that we can use it in different tests. We'll store each endpoint in separate connection file.
import os
def create_connector_files(self, connector_folder):
"""
Method to create connector files and stores it to connector_folder
Args:
connector_folder (str): connector folder
"""
tags = set(tag for endpoint in self.endpoints.values() for tag in endpoint.get("tags", []))
for tag in tags:
tag_data = {name: data for name, data in self.endpoints.items() if tag in data.get("tags", [])}
stripped_tag = tag.replace("-", "_")
connector_folder_path = os.path.join(connector_folder, f"{self.get_backstage()}{self.get_external()}")
os.makedirs(connector_folder_path, exist_ok=True)
connector_file = f"{stripped_tag}_endpoints.py".replace("-", "_")
with open(os.path.join(connector_folder_path, connector_file), "w", encoding="utf-8"):
self.generate_connector_functions(connector_folder_path, tag_data, stripped_tag)
Then let's add some method to generate connector functions and stores it to folder_path.
import os
import re
# pylint: disable=too-many-locals
def generate_connector_functions(self, folder_path, tag_data, tag):
"""
Method to generate connector functions and stores it to folder_path
Args:
folder_path (str): folder path
tag_data (dict): tag data
tag (str): tag
"""
class_name = "".join(word.title() for word in tag.split("_")) + "Endpoints"
endpoint_names = [
f"{method}_{self.camel_to_snake(re.findall(r'{(.*?)}', last_two_parts)[-1] if '{' in last_two_parts else last_two_parts)}" # pylint: disable=line-too-long
for endpoint_name in tag_data.keys()
for method, *_, last_two_parts in [endpoint_name.split("_")]
]
with open(os.path.join(folder_path, f"{tag}_endpoints.py"), "w", encoding="utf-8") as file_out:
file_out.write(
f"""\"\"\"./connectors/backend_api/{self.get_backstage()}{self.get_external()}/{tag}_endpoints.py\"\"\" # pylint: disable=line-too-long
from ..core import BackendAPICore, BackendResponse
class {class_name}(BackendAPICore):
\"\"\"{self.get_backstage()}{self.get_external()} service has {', '.join(endpoint_names)} endpoints\"\"\"
def __init__(self, connection):
super().__init__('{self.get_backstage()}{self.get_external()}', connection)
"""
)
for endpoint_name, endpoint_data in tag_data.items():
parameters = endpoint_data.get("parameters", [])
method, *_, last_two_parts = endpoint_name.split("_")
second_last_part = (
re.findall(r"{(.*?)}", last_two_parts)[-1] if "{" in last_two_parts else last_two_parts
)
stripped_endpoint_name = f"{method}_{self.camel_to_snake(second_last_part)}"
method, _ = endpoint_name.split("_")[0], "_".join(endpoint_name.split("_")[1:])
path_params = [
self.camel_to_snake(param["name"]).replace("-", "_")
for param in parameters
if param["in"] == "path"
]
required_params = [
self.camel_to_snake(param["name"]).replace("-", "_")
for param in parameters
if param.get("required", False)
]
optional_params = [
f"{self.camel_to_snake(param['name']).replace('-', '_')}=None"
for param in parameters
if not param.get("required", False)
and self.camel_to_snake(param["name"]).replace("-", "_") not in required_params
]
params = ", ".join(required_params + optional_params)
raw_url = f'/{"_".join(endpoint_name.split("_")[1:])}'
endpoint_url = f"{{self.base_url}}{self.camel_to_snake(endpoint_url)}"
if method not in ["post", "put", "patch"]:
url = f"f'{endpoint_url}' + ('?' + '&'.join([f'{{k}}={{v}}' for k, v in params_dict.items()]) if params_dict else '')" # pylint: disable=line-too-long
return_statement = f"return BackendResponse(self.session.{method}(url))"
else:
url = f"f'{endpoint_url}'"
return_statement = f"return BackendResponse(self.session.{method}(url, params=params_dict))"
file_out.write(
f"""
def {stripped_endpoint_name}(self, {params}):
{self.generate_connection_docstring(endpoint_data, stripped_endpoint_name)}
params_dict = {{''.join(word.title() for word in k.split('_')): v for k, v in locals().items() if k != 'self' and v is not None and k not in {path_params}}} # pylint: disable=line-too-long
url = {url}
{return_statement}
"""
)
Well, some explanations for code above. At first, we need to wrap-up code into triple-quotes to not process it while generating. Then, we need to import some base class, and create a class for endpoints. Then, we need to create a method for each endpoint. And, we need to generate docstring for each method. And, we need to generate connection for each method. And, we need to generate return statement for each method. And, we need to generate path and query parameters for each method. And, we need to generate url for each method. And, we need to generate params_dict (which params need to be passed to method).
So, only one thing here is left out of the scope, and it's generation of docstring. Let's add some method to generate docstring for connection.
def generate_connection_docstring(self, endpoint_data, endpoint_name):
"""
Method to generate docstring for connection
Args:
endpoint_data (dict): endpoint data
endpoint_name (str): endpoint name
Returns:
str: generated docstring
"""
parameters = endpoint_data.get("parameters", [])
summary = endpoint_data.get("summary", endpoint_name)
docstring = f'"""\n {summary}\n\n Args:\n'
for param in parameters:
if param["in"] in ["query", "path"]:
param_type = param["schema"].get("type", "unknown")
required_params = " (optional)" if not param.get("required", False) else ""
description = (
f'Parameter {self.camel_to_snake(param["name"])} of type {param_type}'
if not param.get("description")
else param["description"]
)
docstring += (
f' {self.camel_to_snake(param["name"])} ({param_type}){required_params}: {description}\n'
)
response_description = endpoint_data["responses"].get("200", {}).get("description", "No description")
docstring += f'\n Returns:\n BackendResponse object. In case of success, status code is 200. {response_description}\n """' # pylint: disable=line-too-long
return docstring
Your testing API
In general, in Python we're using requests library for API testing. In some other, rare cases, some async library, like aiohttp to make requests and get responses. And, it's good idea to to wrap them into some classes, to use it in our tests (with storing environment, session and other project-specific params). Let's add some base classes for it:
from requests import Response
class BackendAPICore:
"""Base class shared by all Backend services"""
def __init__(self, service, connection):
"""
Initialize the Backend API Core
Args:
service (str): The service to use
connection (Connection): The connection to use
"""
self.service = service
self.connection = connection
self.session = self.connection.session
self.account_id = connection.account_id if connection.account_id else ""
base_urls = {
"prod": "https://{service}.my-test-project.com",
"other": "https://{service}.my-test-project{environment}.com",
}
if self.environment in base_urls:
self.base_url = base_urls[self.environment].format(service=self.service)
else:
self.base_url = base_urls["other"].format(service=self.service, environment=self.environment)
class BackendResponse:
"""
A Backend specific response object which simplifies down the
requests.Response object for Backend API purposes.
"""
def __init__(self, response: Response):
"""
Initialize the Backend Response object
Args:
response (Response): The response object to process
"""
self.ok = response.ok
self.status_code = response.status_code
self.url = response.url
self.__content = None
self.process(response)
<...>
def process(self, response: Response) -> None:
"""
Processes a requests package Response object to update internal state
Args:
response (Response): The object we're going to process
"""
content_type = response.headers.get("Content-Type")
if content_type and "json" in content_type:
self.__content = response.json()
elif content_type and "txt/csv" in content_type:
self.__content = response.content.decode(response.apparent_encoding)
else:
self.__content = response.content.decode("utf-8")
Tests
To generate tests we'll use the same approach as for connections. We'll store each endpoint in separate test file.
import os
import re
def create_test_files(self, test_folder):
"""
Method to create test files and stores it to test_folder
Args:
test_folder (str): test folder
"""
for endpoint, data in self.endpoints.items():
for tag in data["tags"]:
method, *_, last_two_parts = endpoint.split("_")
second_last_part = (
re.findall(r"{(.*?)}", last_two_parts)[-1] if "{" in last_two_parts else last_two_parts
)
endpoint_name = f"{method}_{self.camel_to_snake(second_last_part)}"
test_folder_path = os.path.join(test_folder, f"{self.get_backstage()}{self.get_external()}", tag)
os.makedirs(test_folder_path, exist_ok=True)
test_name = f"test_{endpoint_name}.py"
with open(os.path.join(test_folder_path, test_name), "w", encoding="utf-8"):
self.generate_pytest_functions(test_folder_path, test_name, endpoint_name, data, tag)
Then let's add some method to generate pytest functions and stores it to folder_path.
import os
# pylint: disable=too-many-branches,too-many-arguments,too-many-locals
def generate_pytest_functions(self, folder_path, test_name, endpoint_name, data, tag):
"""
Method to generate pytest functions and stores it to folder_path
Args:
folder_path (str): folder path
test_name (str): test name
endpoint_name (str): endpoint name
data (dict): data
tag (str): tag
"""
formatted_params = []
stripped_test_name = test_name[:-3]
stripped_tag = tag.replace("-", "_")
class_name = "".join(word.title() for word in stripped_test_name.split("_")) + "Endpoint"
random_list = []
param_values_dict = {}
for param in data.get("parameters", []):
temp_param = param
temp_param["name"] = self.camel_to_snake(param["name"]).replace("-", "_").replace("__", "_")
formatted_params.append(temp_param)
wrong_value, missing_value, correct_value = self.process_param(param=param)
if wrong_value is None and correct_value is None and missing_value is None:
wrong_value = missing_value = correct_value = f' #FIXME param type of {temp_param["name"]} is UNKNOWN'
param_values_dict[temp_param["name"]] = {
"wrong_value": wrong_value,
"missing_value": missing_value,
"correct_value": correct_value,
}
if isinstance(wrong_value, str):
if wrong_value not in random_list:
if "random" in wrong_value and "{" not in wrong_value:
random_list.append(wrong_value)
if isinstance(correct_value, str):
if correct_value not in random_list and "{" not in correct_value:
if "random" in correct_value:
random_list.append(correct_value)
required_params = [
param for param in formatted_params if param.get("required", False)
]
params_string = None
for param in required_params:
params_string = ", ".join(
[
f"{p['name']}={param_values_dict[p['name']]['correct_value']}"
for p in required_params
if p["name"] != param["name"]
]
)
if not params_string:
params_string = ""
if random_list:
import_string = f'from utils import {", ".join(random_list).replace("()", "")}'
else:
import_string = ""
with open(os.path.join(folder_path, f"{test_name}"), "w", encoding="utf-8") as file_out:
file_out.write(
f"""\"\"\" ./tests/backend_api/{self.get_backstage()}{self.get_external()}/{tag}/{test_name} \"\"\"
import pytest
{import_string}
@pytest.mark.api
@pytest.mark.{stripped_tag}
@pytest.mark.{self.get_backstage().replace("-", "_")}
@pytest.mark.usefixtures("ensure_{stripped_tag}_endpoints")
class {class_name}(object):
"""
)
for response_code in data["responses"]:
file_out.write(
f"""
def {stripped_test_name}_{response_code}_response(self):
response = self.{stripped_tag}_endpoints.{endpoint_name}({params_string})
assert response.status_code == {response_code}
"""
)
for param in [param for param in formatted_params]:
param_to_remove = ""
if param in required_params:
param_to_remove = f"{param['name']}={param_values_dict[param['name']]['correct_value']},"
file_out.write(
f"""
def test_{stripped_test_name}_403_{self.camel_to_snake(param['name']).replace("-", "_").replace("__", "_")}_missing(self): # pylint: disable=line-too-long
response = self.{stripped_tag}_endpoints.{endpoint_name}({param['name']}={param_values_dict[param['name']]['missing_value']}, {params_string.replace(param_to_remove, "").replace(param_to_remove[:-1], "")}) # pylint: disable=line-too-long
assert response.status_code == 403
"""
)
file_out.write(
f"""
def test_{stripped_test_name}_403_{self.camel_to_snake(param['name']).replace("-", "_").replace("__", "_")}_wrong(self): # pylint: disable=line-too-long
response = self.{stripped_tag}_endpoints.{endpoint_name}({param['name']}={param_values_dict[param['name']]['wrong_value']}, {params_string.replace(param_to_remove, "").replace(param_to_remove[:-1], "")}) # pylint: disable=line-too-long
assert response.status_code == 403
"""
)
file_out.write(
"""
# TODO please do not forget to add missed methods and check, at least border values tests
"""
)
As you can see, here I used class-based approach for tests, and I used pytest fixtures to ensure that endpoints are available. In most cases you do not need to use test class, because it's not a good practice, i.e., you can't use pytest-rerunfailures with it. But, as an example, let's use complicated version of test files. So, in test file (and here - test class), we always will check endpoints for valid responses (e.g. '200'), and all parameters for missing and wrong values (e.g. '403'). And, we need to generate it for each endpoint. And, we need to generate it for each tag. And, we need to generate it for each service. And, we need to generate it for each external/internal part. And, we need to generate it for each backend. And, we need to generate it for each environment. And, we need to generate it for each test. Bot, for sure, most likely, especially when Swagger documentation is not complete, you need to add missed methods and check, so, some manual work is still needed.
Calling generator
Finally, we need to call our generator in some order. Let's add some code (task) to call it.
import time
from urllib.parse import urlparse
def task(swagger_url):
"""Task function that performs the main action"""
print(f"\nGot {swagger_url}, starting processing... {time.ctime()}")
parsed_url = urlparse(swagger_url)
subdomain = parsed_url.netloc.split(".")[0]
print(f"Processing: {subdomain}")
swagger_generator = SwaggerParser(url=swagger_url)
print("\tLoading swagger URL as JSON...")
swagger_generator.load_page()
print("\tProcessing json to dict with endpoints...")
swagger_generator.parse_endpoints()
print("\tProcessing schemes of endpoints...")
swagger_generator.get_schemes()
print("\tCreating connectors API files in 'swagger_connectors'")
swagger_generator.create_connector_files("swagger_connectors")
print("\tCreating API tests files in 'swagger_tests'")
swagger_generator.create_test_files("swagger_tests")
endpoint_list.append(swagger_generator.get_endpoints(swagger_url))
And, at last, run it in parallel for all URLs via multiprocessing.
import multiprocessing
urls = [
"https://some-number-one-backstage.my-test-project.com/swagger/backstage-service-external",
"https://some-number-one-backstage.my-test-project.com/swagger/backstage-service",
"https://some-number-two-backstage.my-test-project.com/swagger/backstage-service-external",
"https://some-number-two-backstage.my-test-project.com/swagger/backstage-service",
]
endpoint_list = []
if __name__ == "__main__":
with multiprocessing.Pool() as pool:
pool.map(task, urls)
with open("endpoints_list.txt", "w", encoding="utf-8") as file_list_out:
file_list_out.write(json.dumps(endpoint_list))
Result will looks like folders with connectors code and tests.
Some sceptical thoughts
Actually, I'm not a first who thinks about it. There are some tools, that can do it for you. I.e. swagger-py-codegen or swagger-test-templates, swagger_meqa, merge-dev. But, they are not so flexible, and you can't use it in your project, and you can't modify it. Actually, when your API testing start to comes not just one-by-one feature development, but from bulk changes, or from legacy systems, or covering the gap of automation, you most likely already have some testing and API infrastructure (come BackedAPI core adapters), which needs to be integrated slightly easy into existing API and UI tests, and there your own code and your own skill is only needed.
In other hand, you always must pay attention to automation costs and automation ROI, in some non-repeatable testing tasks just manual testing of APIs using curl may be much better than anything else, or smoke-cover by ready-made tools may be enough for you, especially you won't to integrate into supportable and maintainable testing and development infrastructure.
Sometimes, none of these will work due to poor quality of documentation and process maturity, and you need to use some manual work, or even some manual testing, or even some manual testing with some manual work. And, it's ok, because you need to be flexible and use the best approach for your case, not the best approach for the world. So...
Conclusion
This generator significantly reduces time and efforts for generation of API tests, at least skeletons for them. Using this approach with some file-existence checker may help to keep your API testing infrastructure is up-to-date with backend API changes. Moreover, you can save the states of tests and check for changes at backend side to update tests in automatic way, or, at least at semi-automatic. And, you can use it for smoke poking API endpoints, that at least backend works well. And, you can use it for generating test data, to use it in feature ramp-up.
Well, I hate API testing, and best way to deal with it is to automate it. And, I hope, this article will help you to do it. Delegate. Automate. Rule them all.